Transforming the Afro-Caribbean World Digital Methods Mini-Site
Digital Sources
and Digital Methods
some considerations
This mini-site is intended to serve as a reference for discussions at the Transforming the Afro-Caribbean World (TAW) project workshop (and beyond), which are aimed at designing a potential large-scale research collaboration to investigate the migration of Afro-Caribbean laborers between 1903 and 1920.
Varieties of Sources and Data
The central question of this part of the TAW project and workshop is:
What stuff do we have and what can we do with it?
Responding to this practical question requires a brief discussion of the conceptual background to digital sources and methods and their relation to the rest of research. We need to think carefully about how what we've considered "sources" become "data" — and, in this case specifically, data that is tractable to "computation".
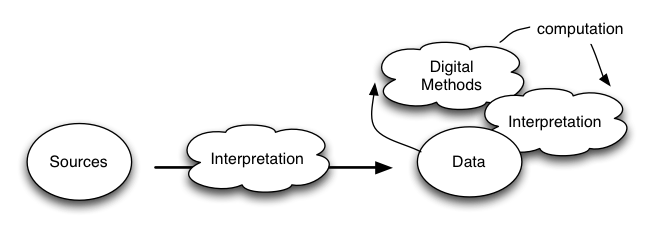
For the TAW project, some of the "sources" (considered so far) are reports (censuses), other official documents, personal narratives, as well as books and newspapers. As humanists, we're already cognizant that the boundaries of a "source" are hard to define precisely — some object plus a (temporally- and culturally-specific) interpretive reaction. So, we proceed from an assumption that:
"Data" from any source is really an epistemic process not a thing.
Following from this assumption, when we talk about digital methods we need to think flexibly about "computation" —
the data we might need to compute is not coterminous with discrete attributes of the original sources.
If we start from a source that is a printed document, in being processed by a human (through transcription and/or text encoding) or by a computational process (optical character recognition), the resulting data has passed through a number of intermediate and interpretive steps (reading, or analysis of light and dark pixel values) and this resulting data can then be considered tractable to further digital methods in a number of ways:
Through this frame, we'll explore some of the possibilities of the data relevant to TAW.
- Crymble, Adam. “Project funding and economical sustainability in historical research”
Further reading
(Other) Text Analytics
After many decades of computational text processing and research, "search" as implemented in major software libraries is a complex text-analytical procedure focused on retrieval. There are other kinds of analytical operations that might be performed against collections of digital text:
Using natural language processing to identify "named entities"
We can also look for "topics" in these collections of text using statistical models
- Digital Scholarship Lab, University of Richmond. “Mining the Dispatch”
Further reading
- Essay Contest texts
- Public domain books texts
- Canal Record newspaper texts,1907-1921
Related data files
Structured Data and Databases
- McDaniel, Caleb. “The Anatomy of an Ad”
- Lincoln, Matt. "Confabulation in the humanities"
Further reading
- Structured transcriptions (CSV)
Related data files
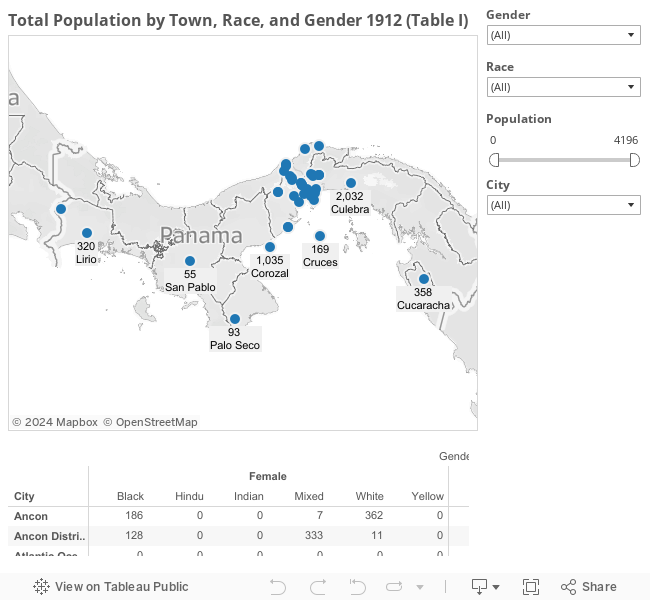
Data Illustration, Data Visualization, and Mapping
- Pleiades Project. Digital gazeteer
Further reading
- Data tables from the 1912 United States Census